如何使用 Machine-Learning 去處理一些非規則性的資料
在 iCHEF,我們會利用政府公開的資料做一些處理並加以利用,經濟部商業司(Ministry of Economic Affairs,R.O.C.) 以下簡稱 MOEA 就是其中一個我們會利用的資料。
MOEA 會在每個月10號釋出一些公司或者商業的登記資料,這些資料的格式是 PDF,內容則有點像是 EXCEL的樣式。
分析資料
工具
所謂工欲善其事,必先利其器,分析之前要先準備好工具
而處理的工具,我們使用的是 python,下面列出最主要的工具
- PDFMiner 處理 PDF 的工具
- scikit-learn ML工具
- pandas/numpy/scipy python 數據分析的好用工具
思考
謀定而後動,在開始處理資料之前,我們先來看看我們要處理的資料是什麼樣子
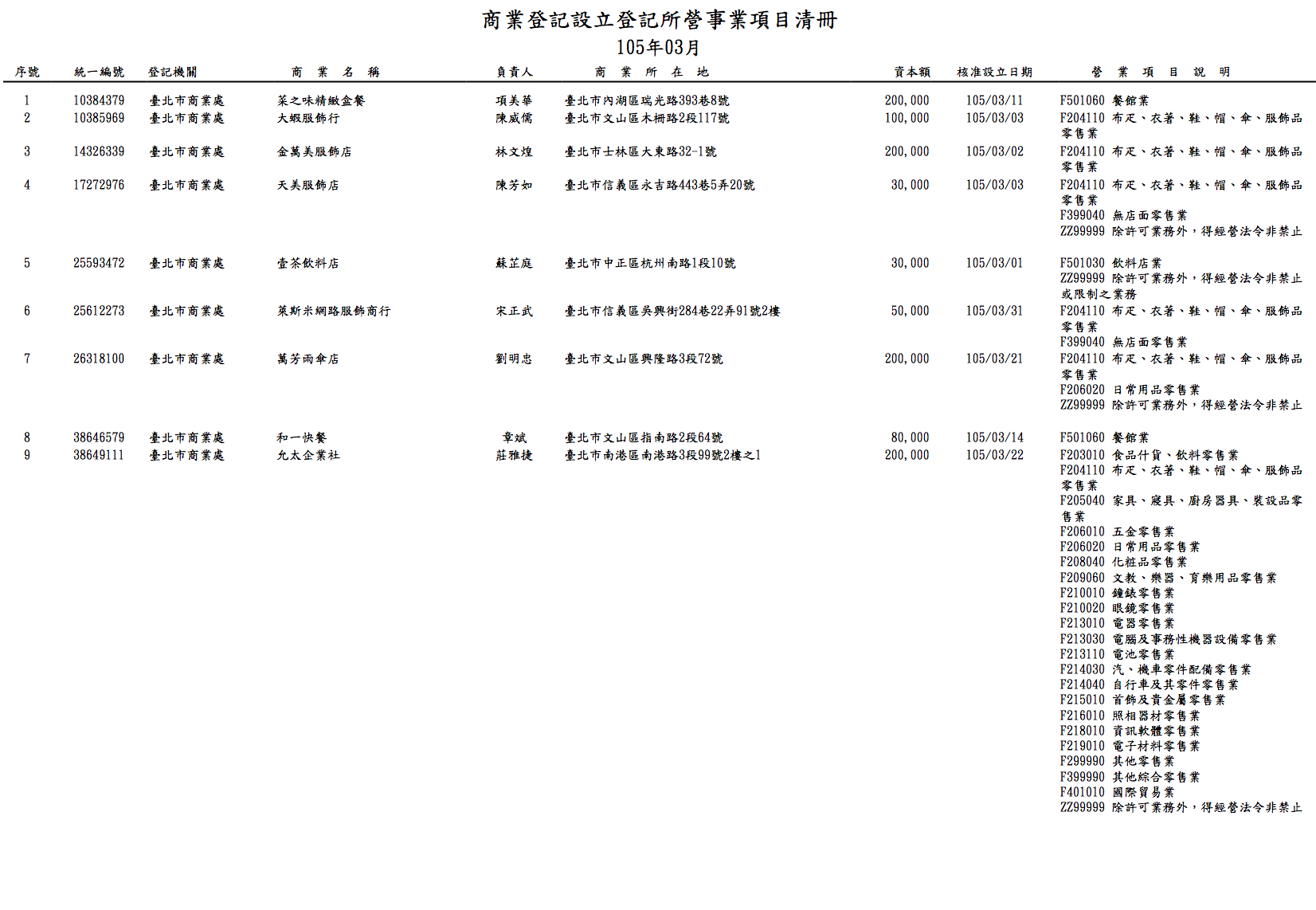 上圖是 PDF 內其中一頁,可以看到大致上跟
上圖是 PDF 內其中一頁,可以看到大致上跟 EXCEL 一樣,除了最後面營業項目說明除外,而通常我們的觀念會想要最後一欄,歸類在同一行的營業人,也就是下圖的概念。
工具特性
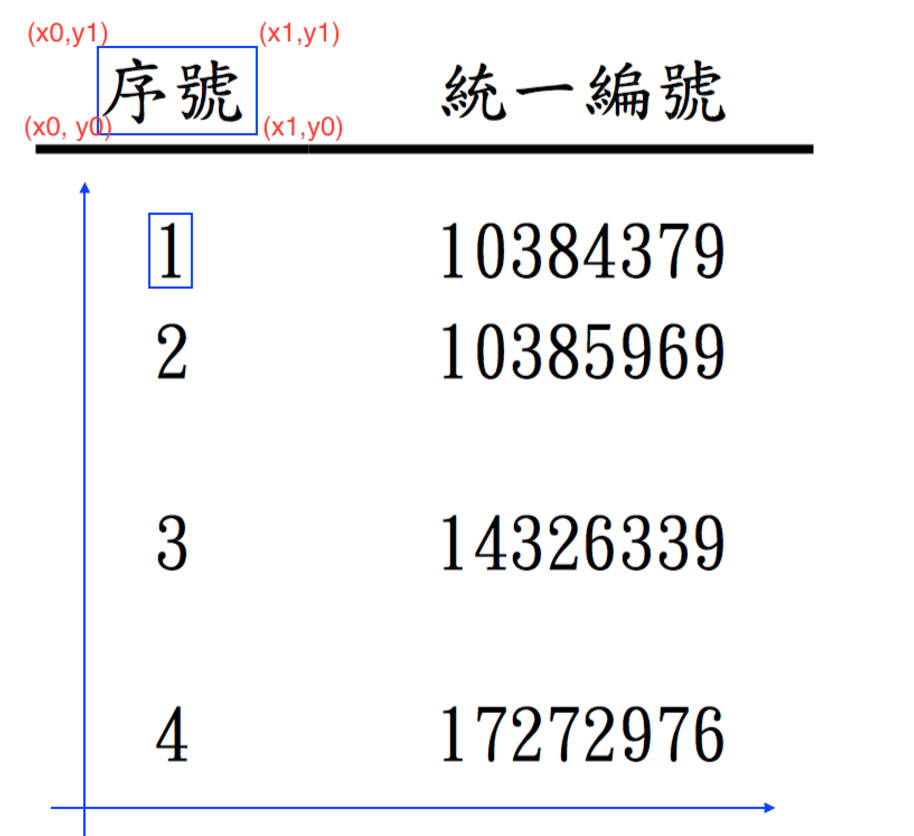
PDFMiner 是將PDF的內容變成座標形式回傳的,以下圖為例
『1』一個字就有一組四個(x, y)座標,座標是由左下角開始,x往右變大,y往上變大
字或者詞的判斷則是由下面的圖來解釋如何運作的
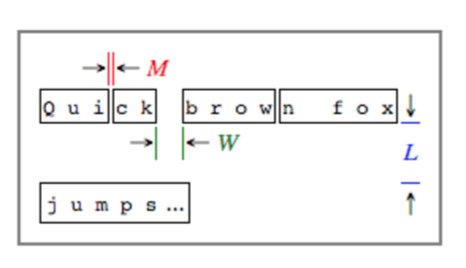
- M 表示兩個『字』之間的水平距離,如果大於某個值會判斷成兩個詞
- W 表示兩個『詞』之間的水平距離,如果大於某個值會判斷成兩個詞
- L 表示兩個『詞』之間的垂直距離,如果大於某個值會判斷成兩個斷行
資料特性
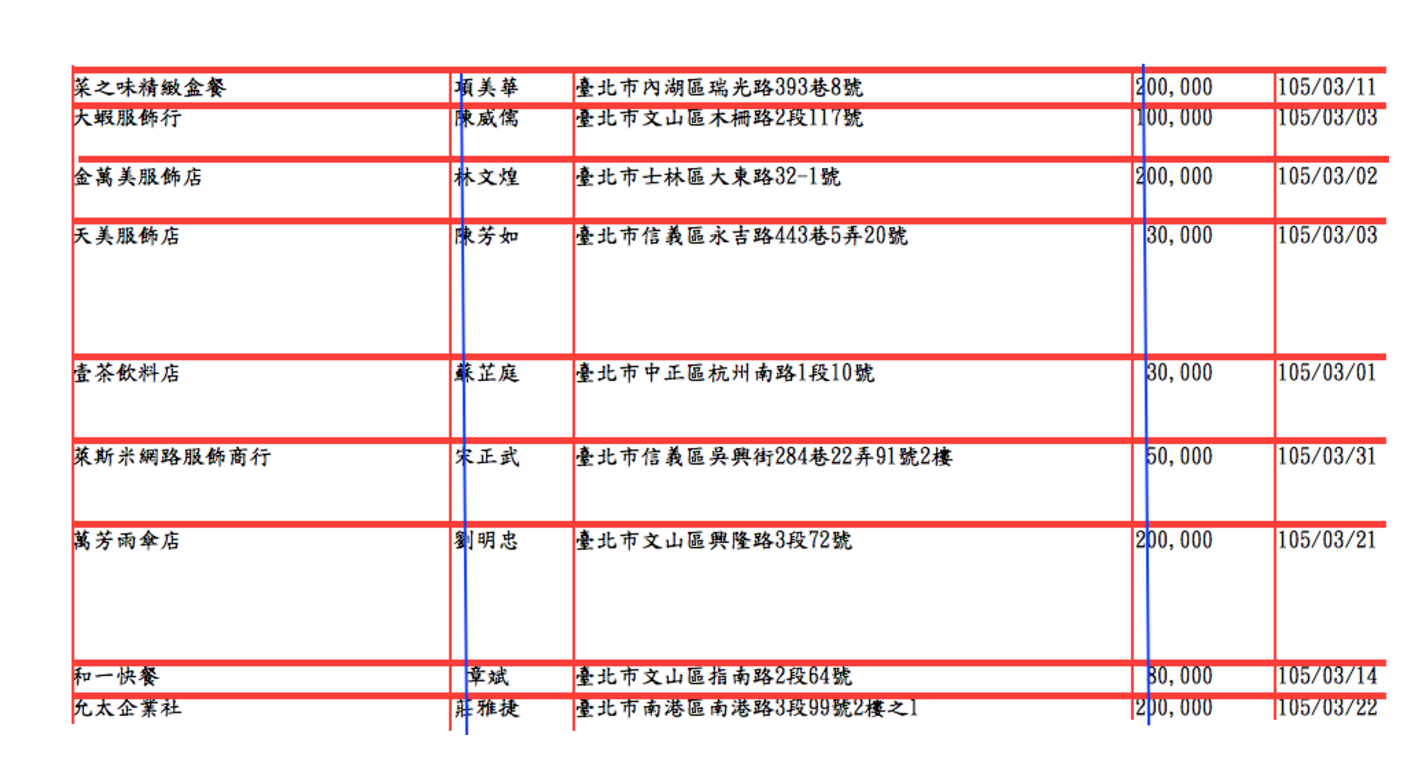
上圖可以很清楚地知道,欄位其實在某些地方有些不一樣(藍色線標明的地方),像是名字因為兩個字置中而導致起始位置跟三個字的地方有些不一樣,大部分欄位都是靠左對齊,資本額的地方卻是靠右對齊,造成起始座標很難歸納出一個範圍。
在分行的地方相對欄位來說,則是比較簡單的,可以藉由字詞 y 的高度來判斷多少範圍內是屬於同一個營業人的情況
例如:
- y的高度 (0, 484] 屬於最下面序號『9』的營業人
- y的高度 (484, 515] 屬於最下面序號『8』的營業人
解決問題
上述提到一個問題,欄位因為起始點不同,所以很難歸納出真正的範圍,這時候機器學習就派上用場了
我們要解決的是分群的問題,分群常用的方法就屬於 KNN 了,KNN 是一種非監督式的機器學習演算法,簡單來說就是物以類聚的概念,我們利用未知座標 X 最鄰近的 N 個點來判斷 X 是屬於哪一個群組,以下圖為例
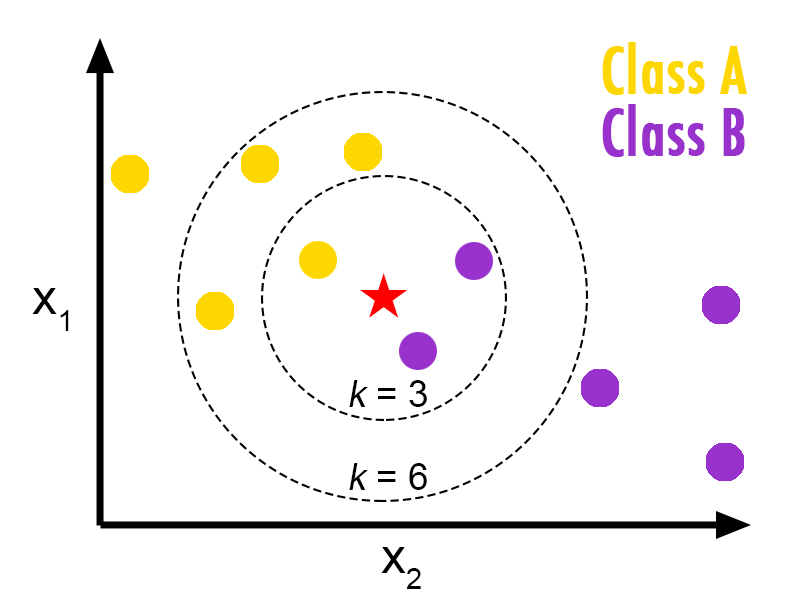 我們已經知道有『黃色』以及『紫色』兩組顏色,今天如果想要判斷『紅色』星星是屬於哪一個群組,KNN 中的 N 值,設定的不一樣,則會帶來不一樣的結果
我們已經知道有『黃色』以及『紫色』兩組顏色,今天如果想要判斷『紅色』星星是屬於哪一個群組,KNN 中的 N 值,設定的不一樣,則會帶來不一樣的結果
如果 N 等於 3,半徑 3 的範圍內有兩個紫色一個黃色,那麼程式就會判斷有33.333%的機率是黃色,66.667%的機率是紫色
如果 N 等於 6,半徑 6 的範圍內有四個紫色兩個黃色,那麼程式就會判斷有66.667%的機率是黃色,33.333%的機率是紫色
我們利用這種物以類聚的概念來對我們的目的資料做 MODEL,MODEL意思是將已經知道的值輸入進去給演算法,然後對新的值做預測,上述的『黃色』以及『紫色』的點就是所謂的 MODEL。
我們將三頁的資料做成 MODEL ,將網狀座標利用我們的 MODEL 做預測,不同的欄位用不同的顏色來表示,跑出N在不同的值下,所產生的結果如下
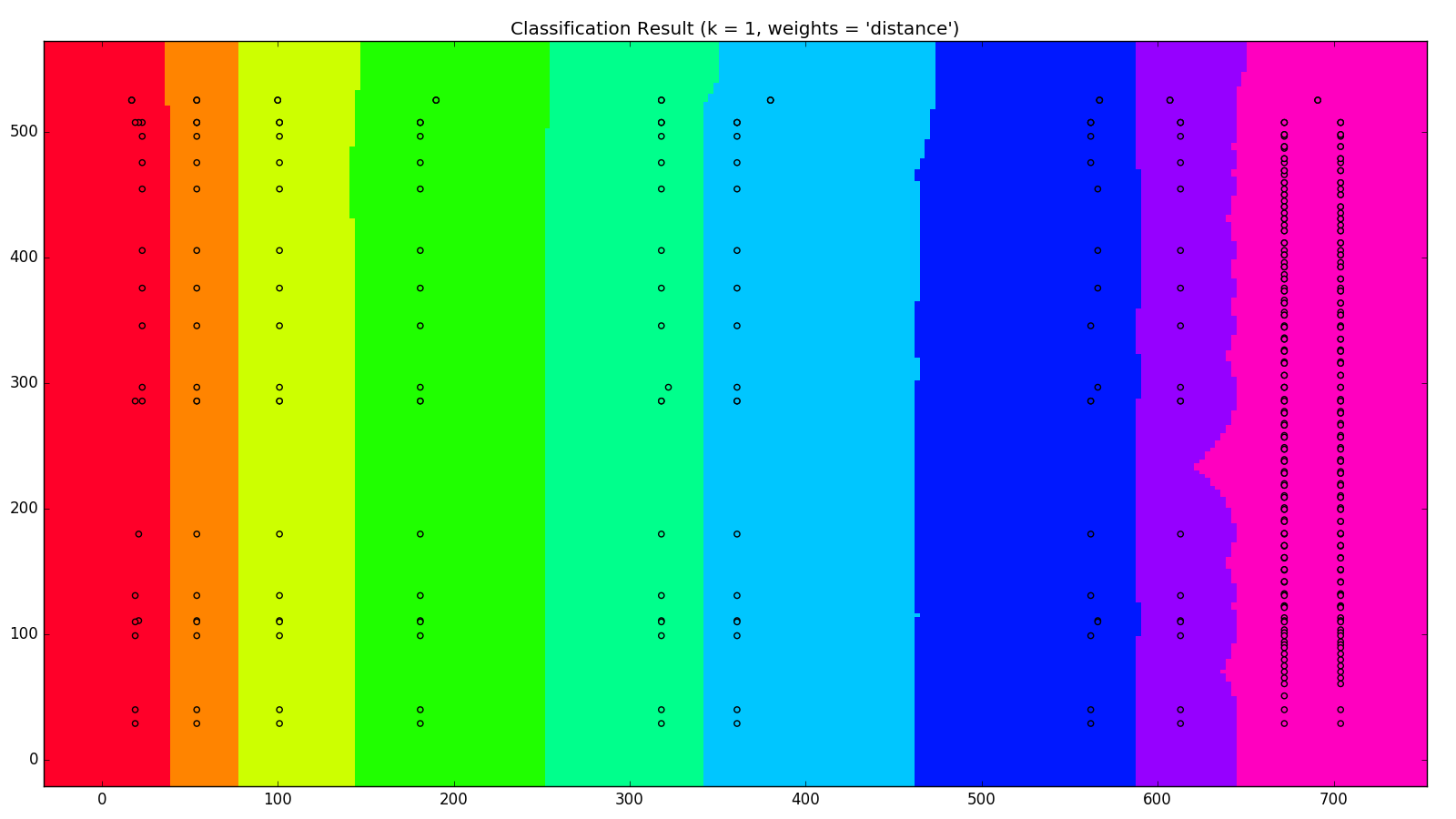
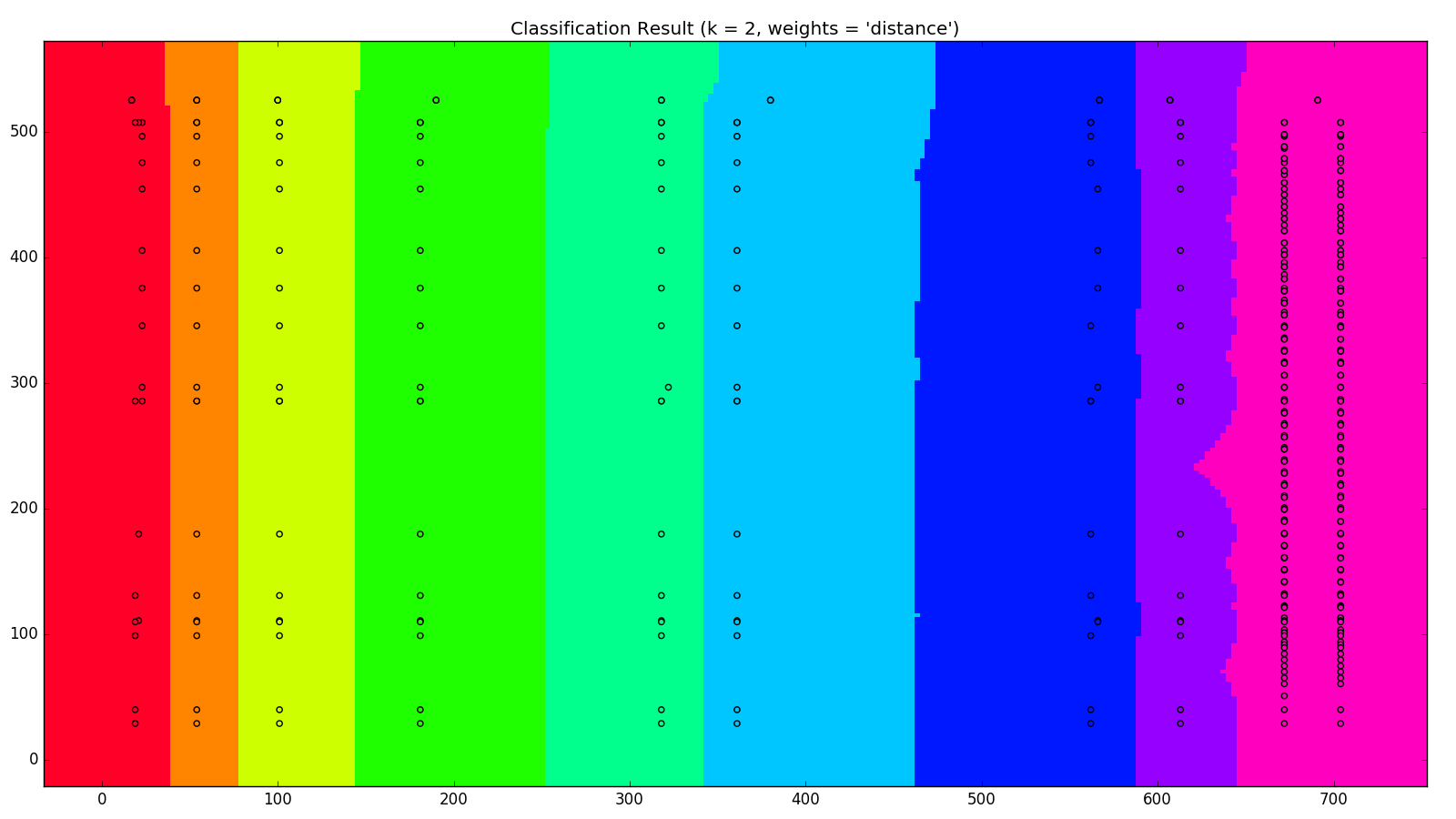
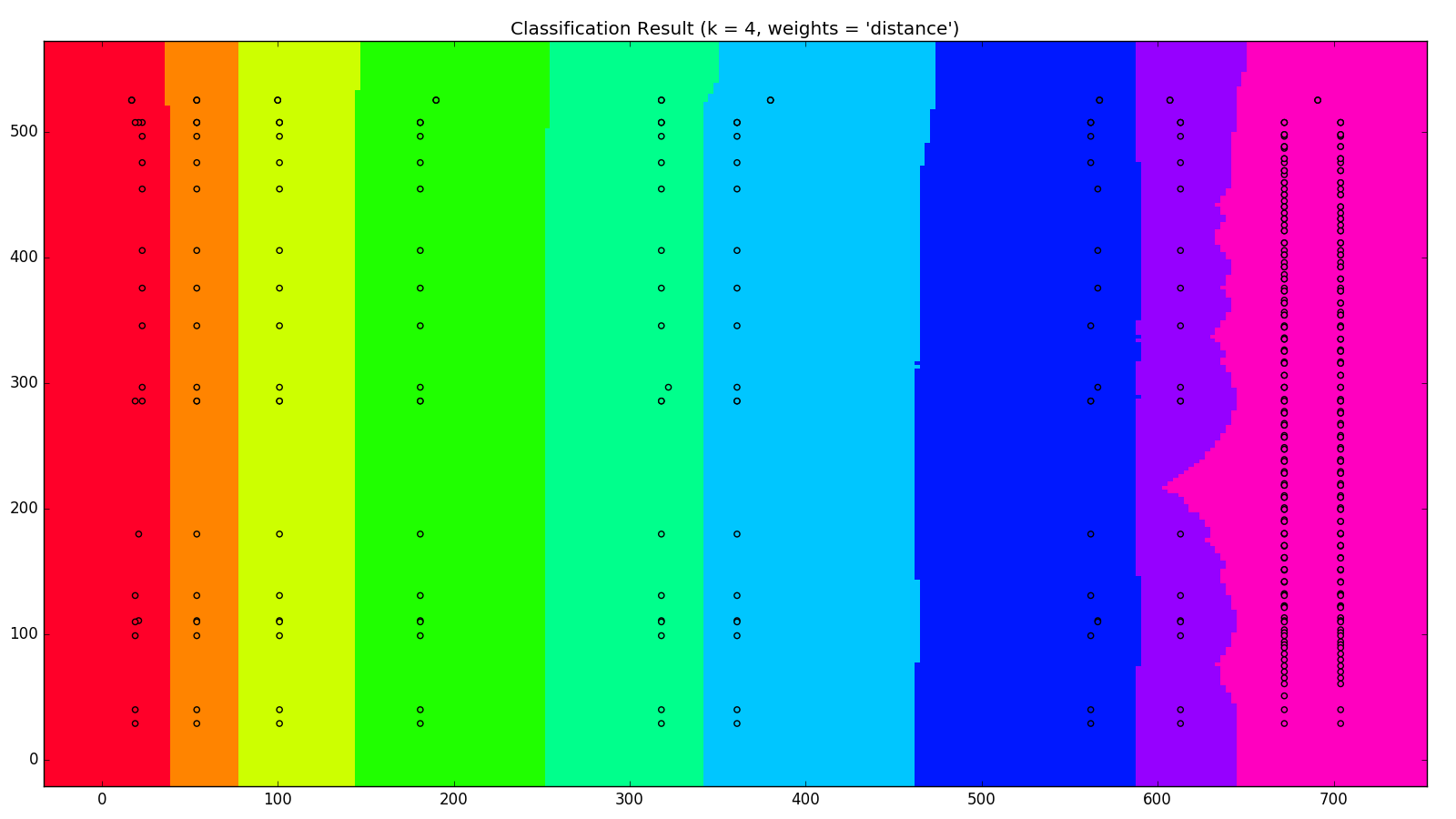
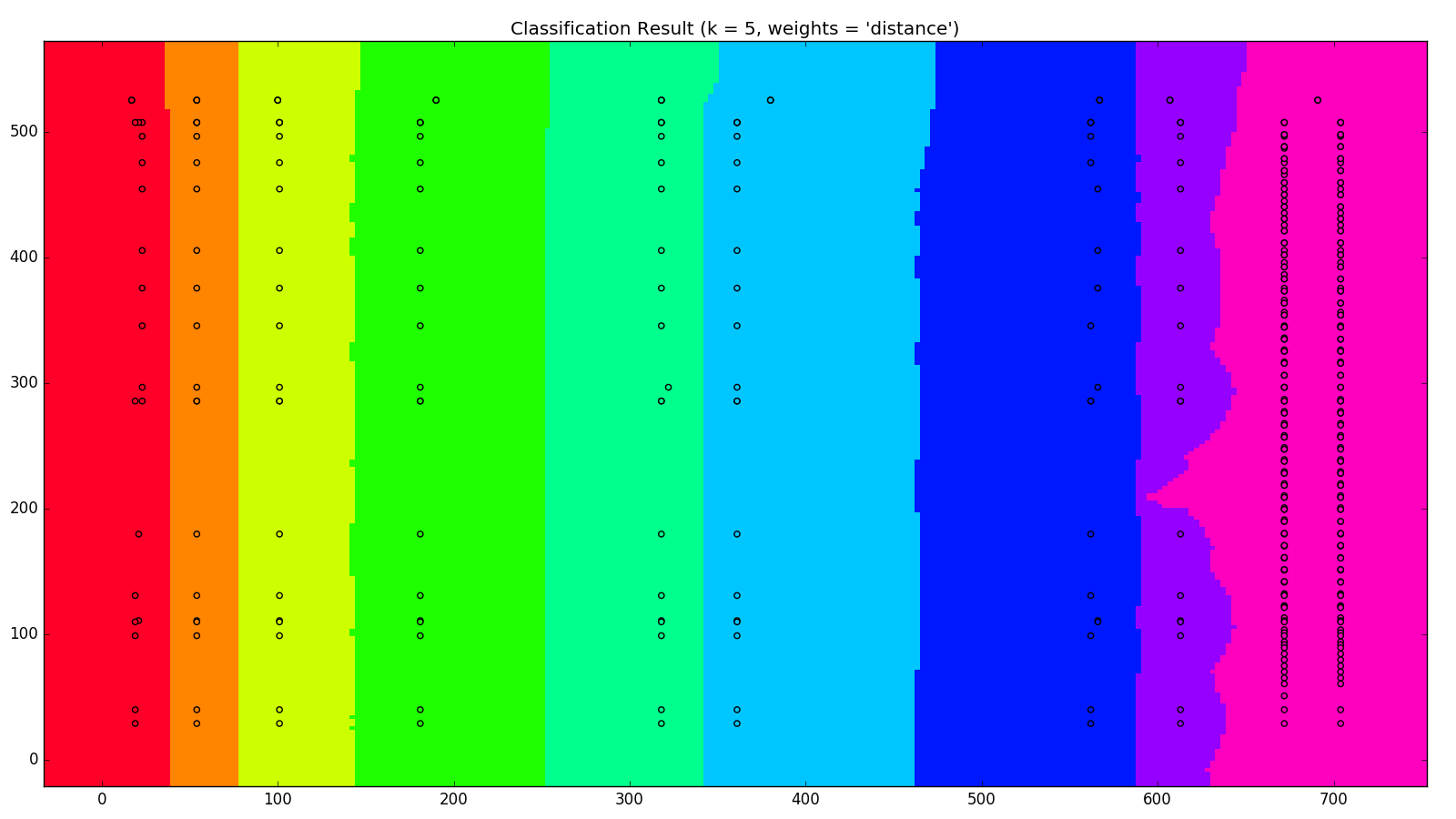
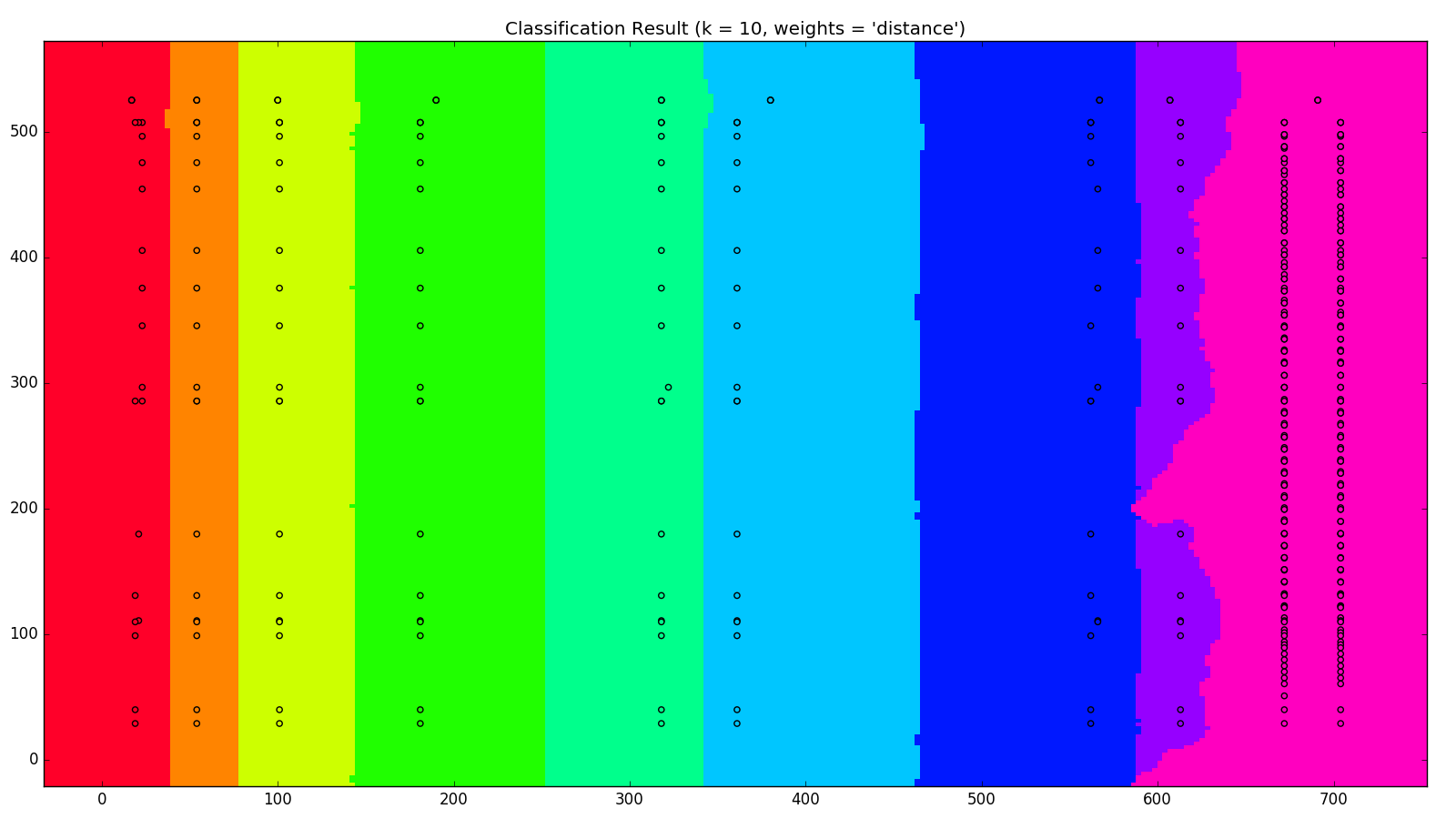
這裡可以看出 N 在 1~2 之間的效果會比 4 以上效果來得好,我們可以利用畫出來的結果來決定使用的 N 值 然而這只有三頁的資料,就可以產生相當程度的分類,機器學習的前途果然不可限量啊!!
Leave a Comment